
Введение
В последние годы популярность систем Retrieval-Augmented Generation (RAG) значительно возросла. Эти системы совмещают модели генерации с компонентами поиска информации, что позволяет им использовать внешние источники данных для более точных и обоснованных ответов. Однако, как показывают практические исследования, RAG-системы часто сталкиваются с проблемами при увеличении объема контекста. В этой статье мы рассмотрим, как контекстное проектирование может помочь преодолеть эти ограничения.

Проблемы традиционных RAG-систем
Основная трудность RAG-систем заключается не столько в процессе извлечения данных, сколько в управлении тем, что входит в окно контекста модели. В типичных сценариях, когда объем извлеченного контекста превышает возможности модели, возникает необходимость в выборе, какой контент следует оставить, а какой исключить. Это приводит к неэффективному использованию памяти и, как следствие, к снижению точности ответов.
Контекстное проектирование: новый подход
Контекстное проектирование отличается от традиционного подхода тем, что между извлечением данных и формированием запроса к модели добавляется слой, который управляет информационными потоками. Этот слой принимает решения о том, какая информация должна быть передана модели, в каком объеме и в каком порядке. Впервые этот подход был описан Андреем Карпатхи в 2025 году и получил название контекстное проектирование.
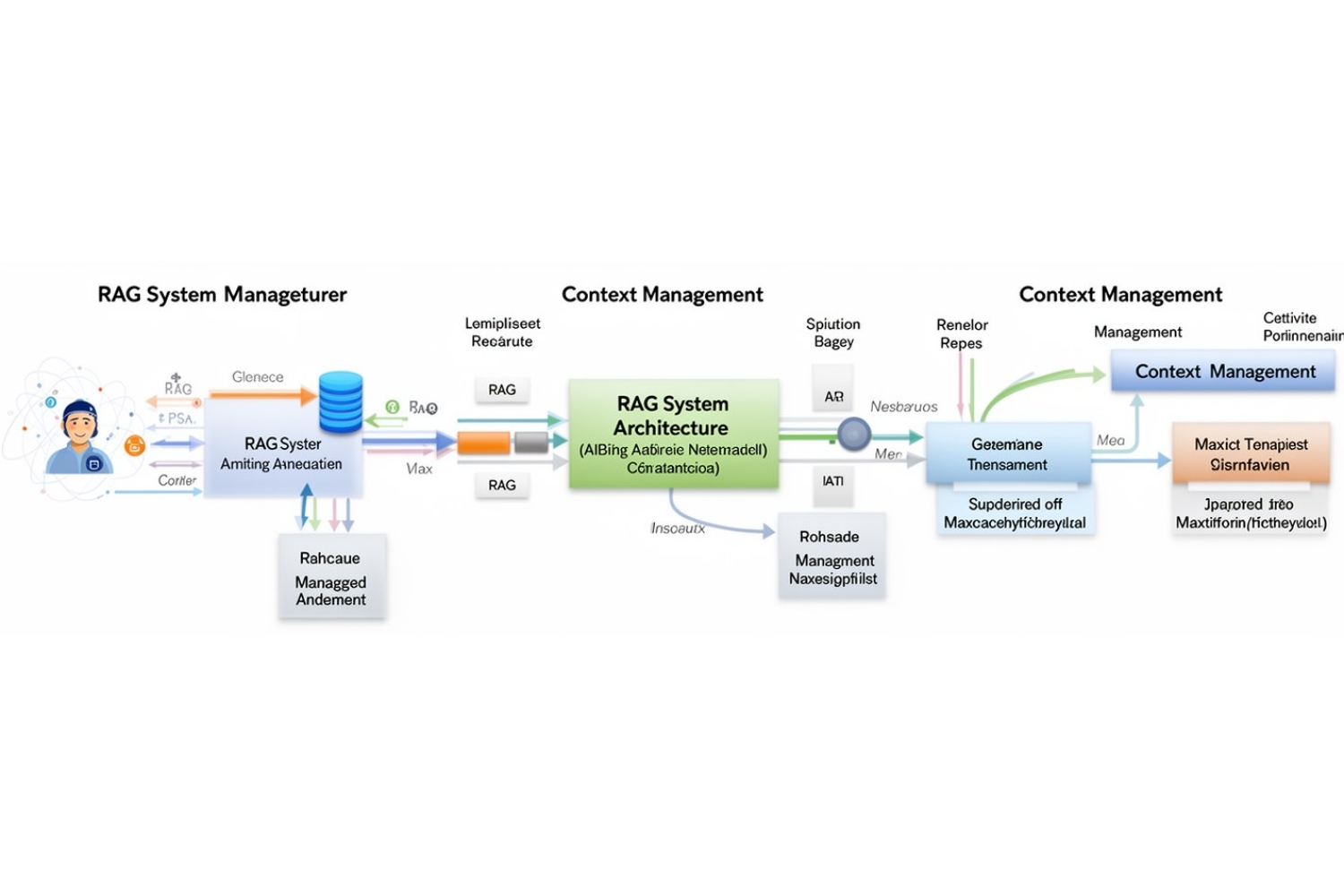
Архитектура полного конвейера
Чтобы эффективно управлять контекстом в RAG-системах, необходимо внедрить несколько ключевых компонентов: извлечение информации, управление памятью, сжатие данных и контроль токенов. Рассмотрим каждый из них более подробно.
Компонент 1: Извлечение информации
Извлечение информации в RAG-системах осуществляется с помощью нескольких методов: ключевые слова, TF-IDF и гибридное извлечение. Каждый метод имеет свои преимущества и недостатки, и их комбинирование позволяет добиться лучших результатов. Гибридный метод, например, использует как ключевые слова, так и семантические векторы для более точного определения релевантных документов.
Компонент 2: Повторное ранжирование
После извлечения информации необходимо решить, в каком порядке документы будут представлены модели. Для этого используется алгоритм повторного ранжирования, который комбинирует баллы извлечения с важностью тега документа. Это позволяет повысить приоритет документов, содержащих ключевые слова, такие как "память" или "контекст".

Компонент 3: Управление памятью
Управление памятью — это ключевой компонент, который часто упускают из виду. Простое скользящее окно может привести к потере контекста или, наоборот, к его избыточности. Решением является использование экспоненциального затухания, которое позволяет управлять значением каждого элемента памяти в зависимости от его важности и времени последнего использования.
Компонент 4: Сжатие контекста
Когда объем извлеченного контекста превышает доступный бюджет токенов, необходимо сжать информацию. Для этого используется несколько стратегий: обрезка, выбор предложений и извлечение релевантных фрагментов. Каждая из этих стратегий имеет свои преимущества и недостатки, и выбор зависит от конкретной задачи.
Компонент 5: Контроль бюджета токенов
Для эффективного управления контекстом необходимо контролировать распределение токенов между различными частями запроса. Это позволяет избежать переполнения и обеспечивает более целесообразное использование доступных ресурсов модели.
Заключение
Контекстное проектирование открывает новые возможности для улучшения RAG-систем, делая их более эффективными и устойчивыми к изменениям контекста. Внедрение предложенных компонентов позволяет улучшить качество и релевантность ответов, обеспечивая более глубокое понимание и использование информации.







