В условиях, где на карту поставлена безопасность, таких как здравоохранение и автономное вождение, важно понимать, почему модель искусственного интеллекта делает определенные прогнозы. Это необходимо для того, чтобы пользователи могли доверять ее выводам.
Проблема объяснимости моделей ИИ
Современные модели искусственного интеллекта, такие как модели компьютерного зрения, часто работают как «черные ящики». Они могут выдавать высокоэффективные прогнозы, но не способны объяснить, какие факторы повлияли на их решения. Это ограничивает их применение в областях, где ошибки могут иметь серьезные последствия.
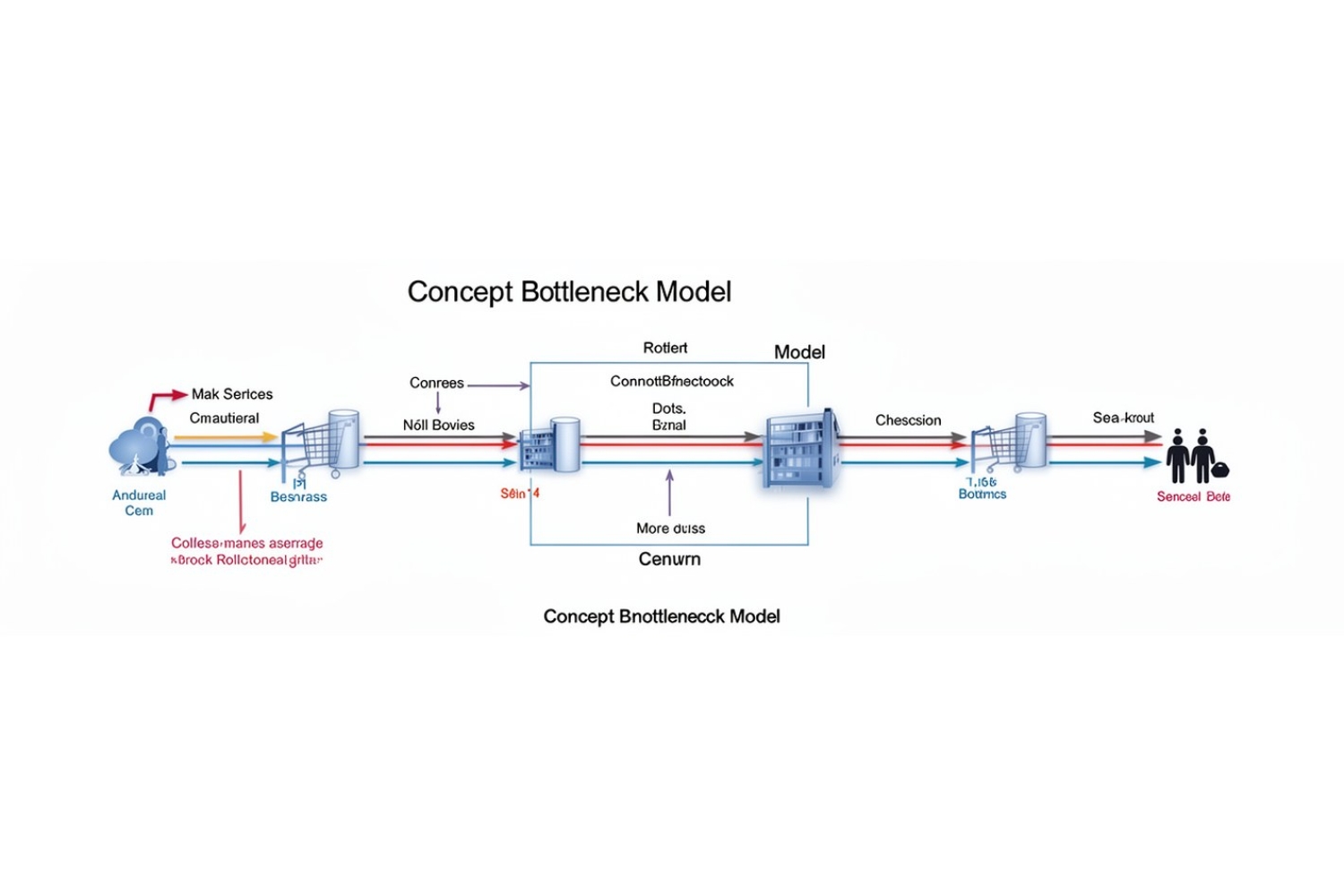
Концептуальные модели с узким местом
Одним из методов, позволяющих решать эту проблему, является использование концептуальных моделей с узким местом (Concept Bottleneck Models, CBMs). Эти модели вводят промежуточный этап, на котором сначала предсказываются концепции, а затем на их основе делается финальный прогноз.
Например, модель, определяющая виды птиц, может сначала выбрать такие концепции, как «желтые лапы» и «синие крылья», прежде чем предсказать, что это ласточка. 
Новый подход от MIT
Исследователи из MIT предложили новый метод, который улучшает точность и объяснимость таких моделей. Они предложили извлекать концепции, которые модель уже «выучила» во время обучения, и превращать их в текст, понятный человеку.
Использование автоэнкодеров и мультимодальных языковых моделей
Метод включает в себя использование разреженных автоэнкодеров, которые выбирают наиболее релевантные признаки, и мультимодальных языковых моделей, которые описывают эти концепции на естественном языке. Такой подход позволяет избежать проблем с информационной утечкой, когда модель может использовать неизвестные или нежелательные концепции.
Преимущества и результаты
В ходе сравнительных испытаний с существующими CBMs, новый метод дал более высокую точность прогнозов и более ясные объяснения. 
Перспективы и вызовы
Несмотря на очевидные успехи, остаются вызовы, связанные с компромиссом между интерпретируемостью и точностью. Исследователи планируют масштабировать метод, используя более крупные языковые модели для аннотирования больших наборов данных.
Эта работа открывает перспективы для создания более интерпретируемых и доверительных систем ИИ, а также для интеграции с символическими системами и графами знаний. Это может стать важным шагом на пути к более прозрачным и ответственным технологиям.