

Введение в Vision Language Models
Современные модели Vision Language (VLM) представляют собой сложные архитектуры, которые объединяют визуальные и текстовые данные, чтобы создавать более глубокие и осмысленные представления. В этой статье мы детально рассмотрим, как такие модели обучаются и какие архитектурные решения лежат в их основе.
Почему не обучать с нуля?
Обучение моделей с нуля — процесс крайне затратный с точки зрения времени, ресурсов и данных. Вместо этого исследовательские лаборатории используют предварительно обученные текстовые модели и дообучают их для добавления визуальных возможностей. Это позволяет значительно сократить затраты и улучшить качество конечной модели.
Архитектура Vision Language Models
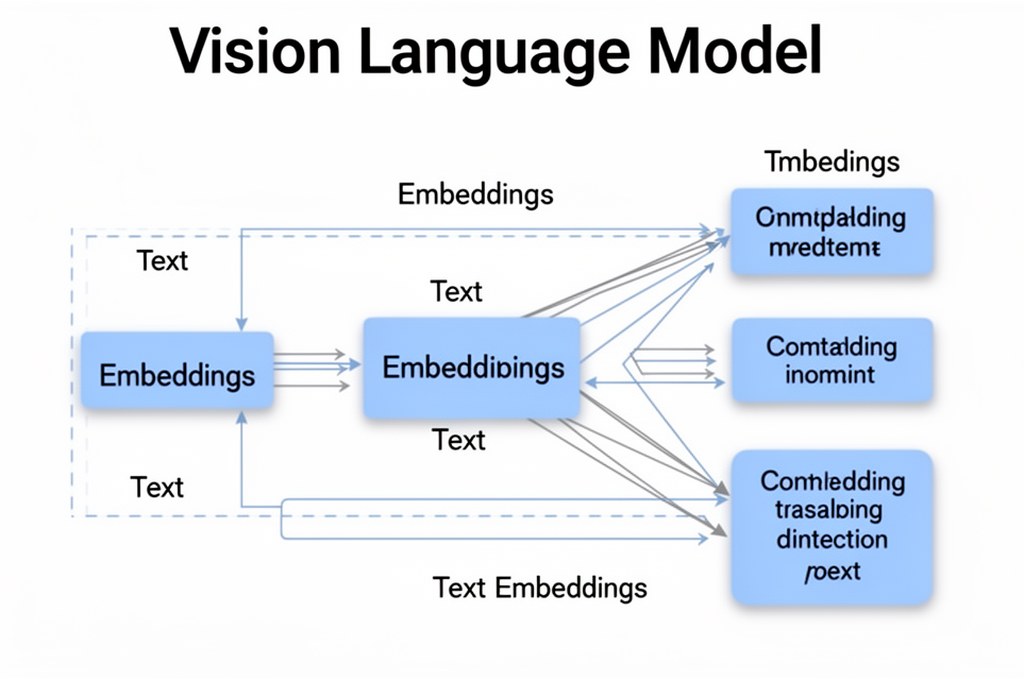
1. Image Backbone
Image Backbone — это компонент, который преобразует сырые изображения в векторные представления. Современные модели, как правило, используют Vision Transformers (ViT) для этой задачи. ViT делят изображение на патчи и применяют к ним слои самовнимания для генерации последовательности векторных эмбеддингов.
2. Adapter Layer
Adapter Layer — ключевая часть, которая преобразует изображения в текстово-совместимые эмбеддинги. Популярный подход — использование Q-Former, который был представлен в статье BLIP-2.
- Q-Former обучается на парах изображение-текст, создавая общее пространство эмбеддингов.
- Вводятся кросс-внимательные слои для объединения визуальных и текстовых эмбеддингов.
3. Language Layer
На завершающем этапе Language Layer принимает адаптированные эмбеддинги и генерирует текст на их основе. Это позволяет модели создавать текстовые описания на основе визуальных данных.
Преимущества и перспективы использования VLM
Использование Vision Language Models открывает широкие перспективы в различных областях, таких как автоматическая аннотация изображений, улучшение систем рекомендаций и создание более интуитивно понятных интерфейсов для взаимодействия с пользователем. В будущем эти модели могут стать основой для более сложных систем, объединяющих не только текст и изображение, но и другие виды данных.
В заключение, развитие VLM позволяет значительно расширить возможности искусственного интеллекта, делая его более универсальным и применимым в различных сценариях.







