
Введение в модели Vision Language
Современные модели Vision Language (VLM) представляют собой мощные инструменты, способные обрабатывать как текст, так и изображения. Однако обучение таких моделей с "нуля" — задача крайне трудоемкая и неэффективная. Вместо этого исследовательские лаборатории предпочитают использовать уже обученные текстовые модели, добавляя им "зрительные" способности. В этой статье мы подробно обсудим архитектуры, лежащие в основе современных VLM, и процесс их дообучения.
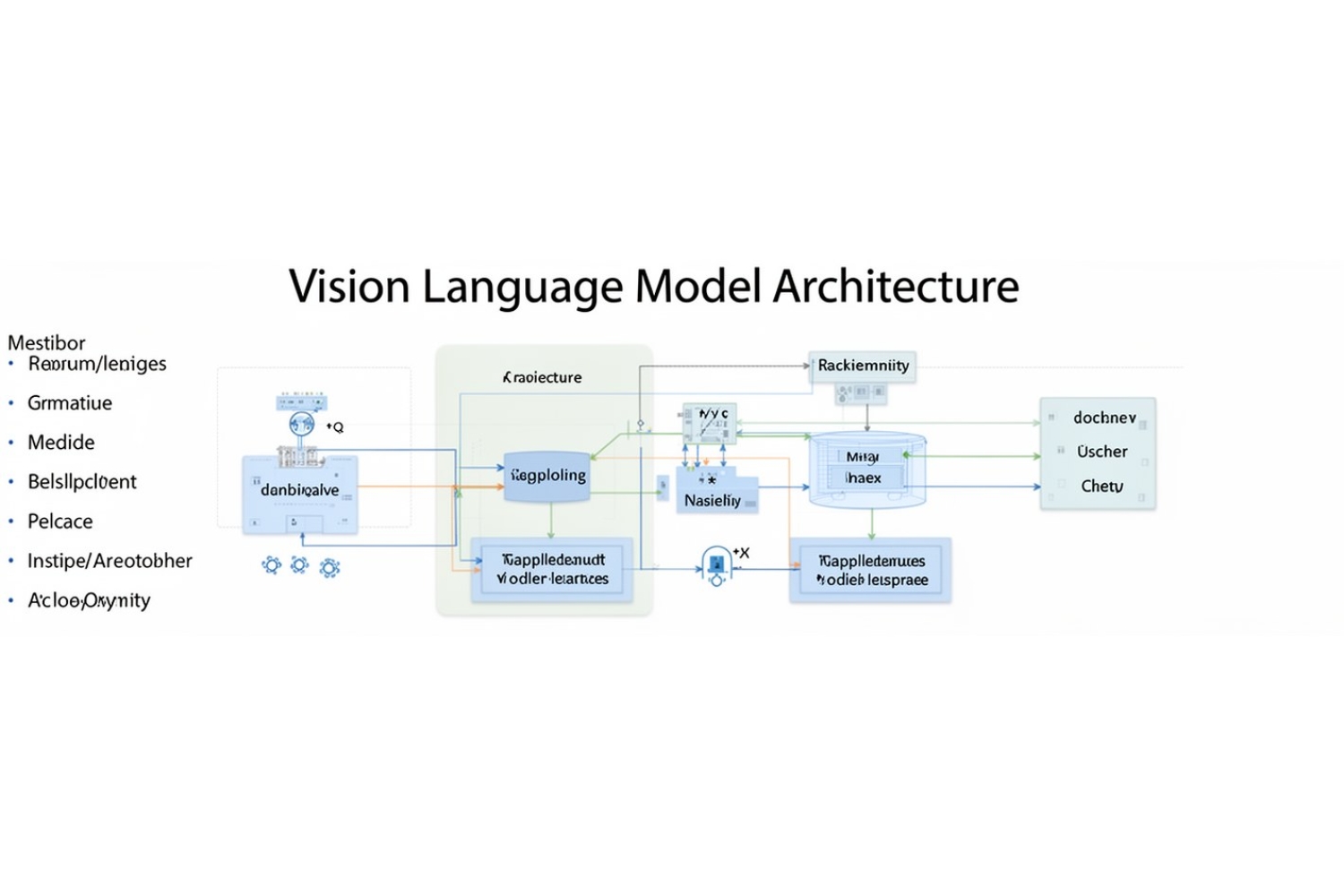
Основы архитектуры Vision Language Models
Образная основа (Image Backbone)
Образная основа — это часть модели, которая преобразует необработанные изображения в числовые представления, которые понимает нейронная сеть. Чаще всего используются предварительно обученные модели, такие как Vision Transformers (ViT), которые принимают изображение, разбивают его на патчи и обрабатывают через слои самовнимания, чтобы создать последовательность векторных представлений.
В большинстве исследований VLM принято держать весовые коэффициенты образной основы неизменными, чтобы избежать переобучения и сократить расходы на вычисления.
Адаптерный слой (Adapter Layer)
Адаптерный слой преобразует числовые представления изображения в текстосовместимые векторы. Это самый сложный этап, так как необходимо выбрать подходящие архитектуры и функции потерь. Одним из популярных подходов является использование модели Q-Former, которая была представлена в статье BLIP-2.
- Q-Former: Включает обучаемые "запросные" векторы, которые помогают адаптировать визуальные векторы в текстовые токены. Обучение происходит на основе мультимодальных наборов данных, например, Conceptual Captions.
- Функции потерь: Включают Image-Text Contrastive Loss, Image-Text Matching Loss и Image-Text Generation Loss, каждая из которых фокусируется на различной степени связи между текстом и изображением.
Языковой слой (Language Layer)
Языковой слой использует адаптированные векторы изображения для генерации текста. Для этого можно использовать небольшие языковые модели, такие как SmolLM2-135M. Процесс обучения здесь менее сложен, чем в случае Q-Former, так как основное внимание уделяется интеграции визуальных и текстовых данных.
Заключение и перспективы
Модели Vision Language открывают новые горизонты в области искусственного интеллекта, позволяя более эффективно работать с данными, содержащими как текст, так и изображения. Благодаря таким подходам, как использование предварительно обученных текстовых моделей и адаптерных слоев, мы можем преодолеть ограничения традиционных методов обучения. В будущем мы можем ожидать еще большего расширения функциональности VLM, что позволит создавать более сложные и взаимосвязанные системы искусственного интеллекта.







