
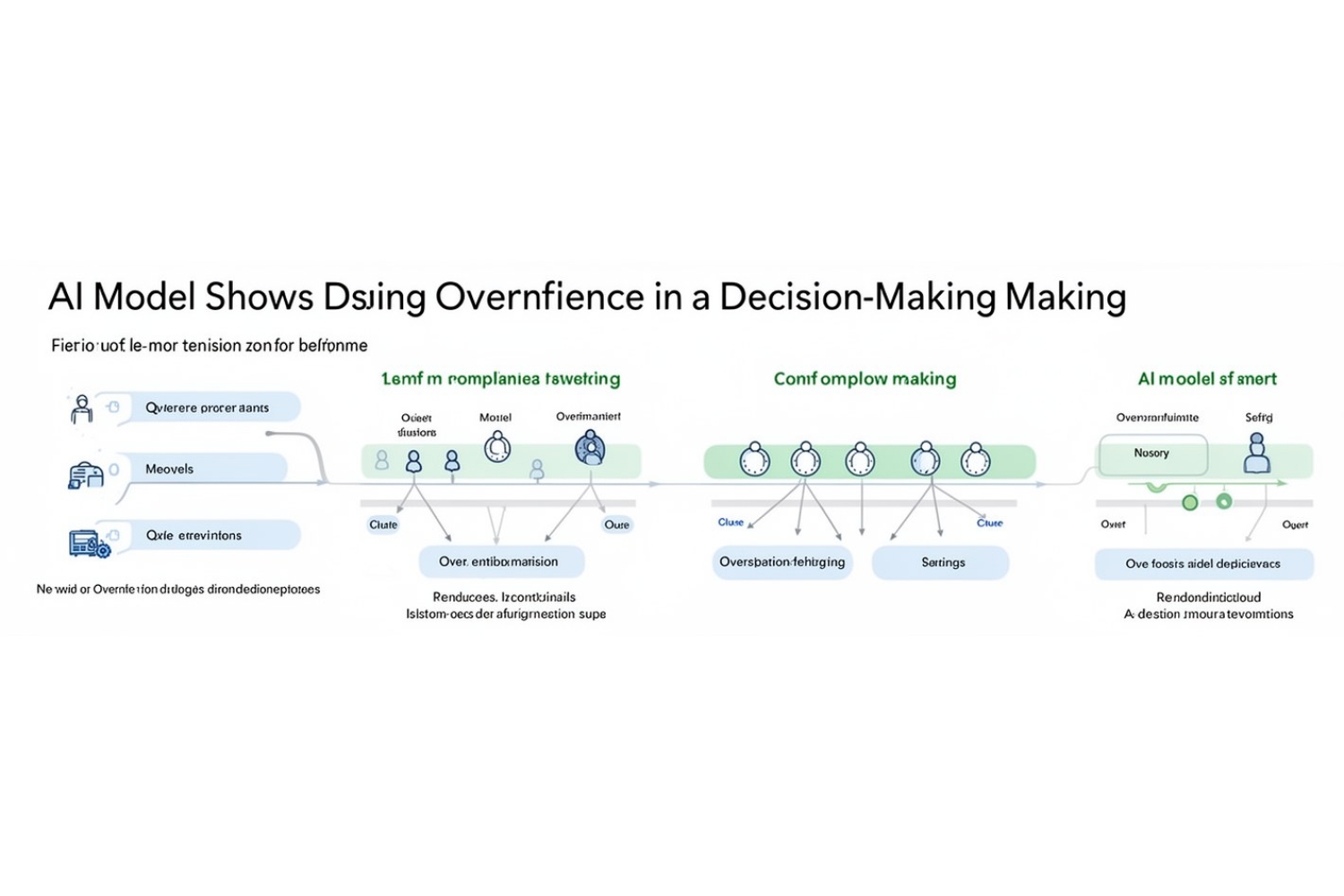
Введение в проблему излишней уверенности языковых моделей
Современные большие языковые модели (LLM) часто поражают своей способностью генерировать убедительные ответы на разнообразные запросы. Однако, как выясняется, эти модели могут быть уверены в своих ответах даже тогда, когда они ошибочны. Это явление, известное как излишняя самоуверенность, вызывает особую озабоченность в областях с высокими ставками, таких как здравоохранение и финансы, где ошибки могут иметь серьёзные последствия.
Традиционные методы оценки неопределенности и их ограничения
Существующие методы оценки неопределенности, как правило, сосредоточены на измерении самоуверенности модели, известной как алеторическая неопределенность. Один из подходов — это многократная проверка ответа модели на один и тот же запрос, чтобы увидеть, насколько она последовательна. Однако, как показывают исследования, модели могут быть уверены в своих ответах, даже если они ошибочны.
Для более точной оценки эпистемической неопределенности — или неопределенности относительно того, насколько правильно выбрана модель для данной задачи — необходимо использовать более сложные методы, которые учитывают разногласия между различными моделями.
Методика MIT: кросс-модельное разногласие
Исследователи из MIT предложили новый подход, который позволяет более точно выявлять самоуверенные, но неверные ответы языковых моделей. Их метод основан на сравнении ответов целевой модели с ответами группы аналогичных моделей. Измерение разногласия между моделями позволяет более точно определить, когда модель ошибочна в своих уверенных предсказаниях.
Для достижения наибольшей точности исследователи использовали ансамбль моделей, которые варьировались по архитектуре и размерам, чтобы обеспечить разнообразие ответов и избежать излишней схожести с целевой моделью. Это позволило создать метрику общей неопределенности (TU), которая сочетает в себе традиционные методы измерения алеторической неопределенности и новый подход к оценке эпистемической неопределенности.
Практическое применение и перспективы разработки
В ходе экспериментов, проведенных на множестве задач, таких как вопросно-ответные системы, математические рассуждения и перевод, новая методика показала превосходство в выявлении ненадежных предсказаний по сравнению с традиционными методами. Она также оказалась более экономичной в плане вычислительных ресурсов, что особенно важно в условиях растущих затрат на обучение и эксплуатацию больших языковых моделей.
Обнаружение эпистемической неопределенности оказалось наиболее эффективным в задачах с единственно правильным ответом, однако подводило в более открытых задачах. В будущем исследователи планируют адаптировать свою методику для улучшения производительности на таких заданиях, а также изучить другие формы алеторической неопределенности.
Это исследование финансируется MIT-IBM Watson AI Lab и открывает новые горизонты в области надежности и точности языковых моделей.







