
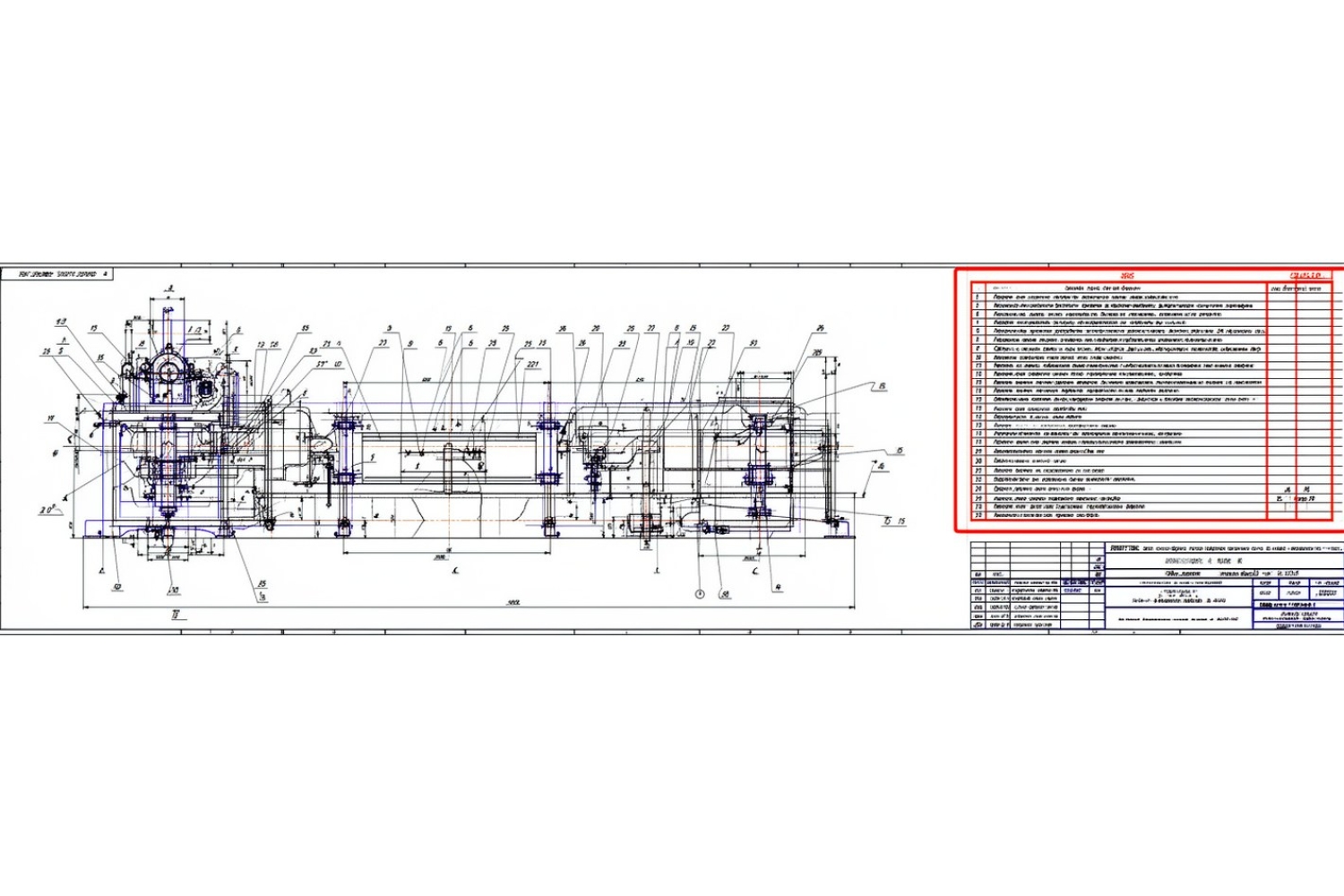
Введение: проблема извлечения данных из инженерных чертежей
Недавно передо мной встал вызов: извлечь ревизионные номера из более чем 4700 PDF-файлов инженерных чертежей. Эти данные были необходимы для миграции на новую систему управления активами. Альтернативой было бы ручное извлечение, что заняло бы около 160 человеко-часов и обошлось бы в более чем 8000 фунтов стерлингов без ощутимой инженерной ценности.
Скрытая сложность «простых» PDF
Инженерные чертежи не являются обычными PDF. Они могут быть созданы в CAD-программах и экспортированы как текстовые PDF, из которых программно можно извлечь текст, или быть отсканированными изображениями с отсутствующим текстовым слоем. Наша задача усложнялась разнообразием форматов и ориентаций чертежей.
Почему полностью ИИ подход был неверным выбором
Использование ИИ для извлечения данных из всех документов было бы дорогостоящим и неэффективным. Вместо этого мы выбрали гибридный подход, где алгоритмы работают в тандеме с ИИ, чтобы справиться с наиболее сложными случаями.
Гибридная архитектура: две стадии извлечения
Стадия 1: Извлечение с помощью PyMuPDF
На первой стадии мы использовали PyMuPDF для детерминированного извлечения текста из PDF-файлов. Эта стадия охватывала около 70-80% нашего корпуса документов, и её применение было бесплатным.
Стадия 2: Использование GPT-4 Vision
Во второй стадии использовался GPT-4 Vision для обработки оставшихся 20-30% документов, где текстовое извлечение не удавалось из-за отсутствия текстового слоя или сложного макета.
Проблемы в производственной среде и их решение
В процессе работы над полным корпусом документов мы столкнулись с проблемами, такими как неоднозначность ориентации документов и галлюцинации модели при использовании ИИ. Мы разработали эвристики для определения правильной ориентации и улучшили инженерное проектирование промтов для решения этих задач.
Результаты и компромиссы
Наш подход позволил достичь 96% точности за 45 минут обработки, с минимальными затратами на API. Это было приемлемо для нашей задачи, и позволило существенно сократить время и затраты на ручной труд.
Заключение: от скрипта до системы
Система, изначально реализованная как командная утилита, была затем переработана в веб-приложение для удобства использования. Она была успешно внедрена в нескольких подразделениях компании для выполнения задач миграции и аудита.
Уроки для практиков
- Начинайте с самого дешевого подхода: детерминированные методы могут быть эффективнее в ряде случаев.
- Валидация на широком наборе данных: избегайте проверки на выборочных примерах, чтобы учесть все возможные случаи.
- Инженерия промтов: относитесь к промтам как к коду, который необходимо тщательно проектировать и тестировать.
- Измеряйте то, что важно для стейкхолдеров: конечный результат важнее используемой технологии.







