Введение в концептуальные модели узких мест
В критически важных областях, таких как медицинская диагностика и автономное вождение, пользователи часто хотят понимать, почему модель ИИ сделала определенный прогноз. Это необходимо для того, чтобы решить, следует ли доверять её выходным данным. Традиционно в таких случаях применяются модели, известные как концептуальные модели узких мест (Concept Bottleneck Models, CBM).
Эти модели добавляют промежуточный шаг, заставляя модель компьютерного зрения сначала предсказать присутствие концепций на изображении, а затем использовать их для окончательного прогноза. Такая система позволяет пользователям понять, на чем основано решение модели.

Новый подход от исследователей MIT
Группа ученых из MIT предложила инновационный метод, который оптимизирует CBM, извлекая уже усвоенные моделью концепции и превращая их в понятный текст. Это позволяет улучшить точность моделей и качество объяснений.
В отличие от традиционных подходов, где концепции заранее определяются экспертами, новый метод позволяет модели использовать концепции, уже изученные в процессе обучения. Это делает объяснения более релевантными и точными.
Механизм работы метода
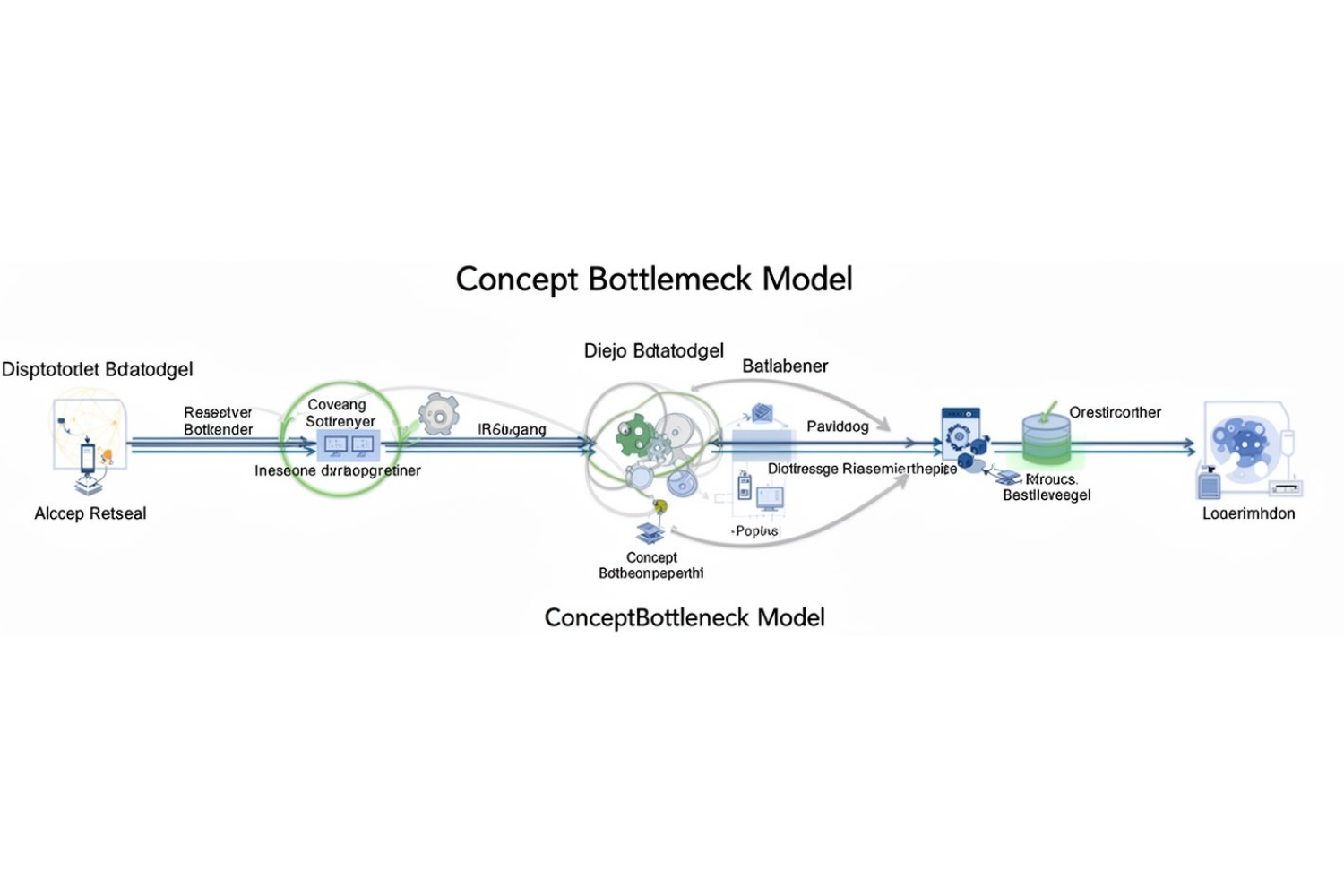
Метод включает в себя использование разреженного автоэнкодера, который выбирает наиболее существенные признаки, изученные моделью, и преобразует их в набор концепций. Затем мультимодальная языковая модель (LLM) описывает каждую концепцию на простом языке.
После этого LLM аннотирует изображения в наборе данных, определяя, какие концепции присутствуют в каждом изображении. Этот аннотированный набор данных используется для обучения модуля концептуального узкого места, который интегрируется в целевую модель.

Контроль и ограничения
Чтобы предотвратить использование неизвестных или нежелательных концепций, исследователи ограничили модель использованием только пяти концепций для каждого прогноза. Это вынуждает модель выбирать наиболее релевантные концепции и делает объяснения более понятными.
Сравнивая свой подход с современными CBM, исследователи MIT достигли наивысшей точности, предоставляя более точные объяснения. Однако, как отмечает один из авторов исследования, Антонио Де Сантис, остается проблема компромисса между интерпретируемостью и точностью.
Перспективы и применение
Новый метод может значительно повысить доверие к ИИ в критически важных системах, таких как здравоохранение и автономное вождение. Понимание внутренней логики моделей поможет пользователям более осознанно принимать решения на основе их прогнозов.
В будущем исследователи планируют изучать возможные решения для устранения утечки информации и масштабировать метод, используя более крупные мультимодальные языковые модели для аннотации больших наборов данных.
Этот прорыв также открывает возможности для интеграции с символическим ИИ и графами знаний, что может привести к более точным и понятным объяснениям, основанным на внутренних механизмах модели.