Введение: необходимость объяснимости ИИ
В современном мире искусственный интеллект (ИИ) играет все более важную роль в различных областях. Однако, когда речь идет о критически важных приложениях, таких как здравоохранение и автономное вождение, пользователи хотят понимать, как ИИ принимает решения. Это необходимо для оценки надежности и безопасности его прогнозов.

Концептуальные модели как мост к пониманию
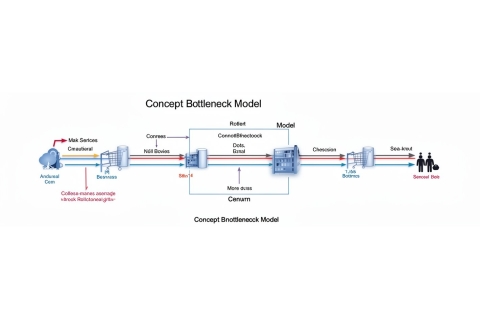
Одним из методов, позволяющих ИИ объяснять свои прогнозы, является моделирование концептуальных узких мест (Concept Bottleneck Models, CBM). Эти модели работают путем разложения процесса принятия решения на понятные человеку концепции, которые затем используются для формирования окончательного прогноза.
Проблемы традиционного подхода
Традиционные CBM требуют заранее определенных концепций, которые могут быть недостаточно точными или не подходить для конкретной задачи. Это снижает точность моделей. Кроме того, модели могут использовать нежелательные или неизвестные концепции, что приводит к утечке информации.
Новый подход от MIT: извлечение концепций из модели
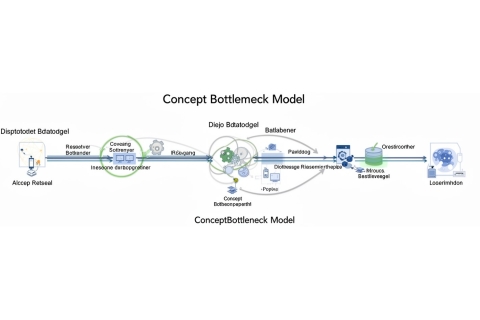
Исследователи MIT предложили альтернативный метод, который извлекает концепции, уже изученные моделью во время обучения, и преобразует их в текст, понятный человеку. Это позволяет улучшить точность и объяснимость прогнозов.
Как это работает
Первоначально используется специальная глубокая обучающая модель — разреженный автоэнкодер, который выбирает наиболее релевантные особенности модели и преобразует их в несколько концепций. Затем мультимодальная языковая модель описывает каждую концепцию на простом языке и аннотирует изображения в наборе данных, выявляя присутствующие и отсутствующие концепции.

Управление концепциями
Чтобы избежать использования неизвестных или нежелательных концепций, модель ограничивают использованием только пяти концепций для каждого прогноза. Это вынуждает модель выбирать наиболее релевантные концепции и делает объяснения более понятными.
Результаты и перспективы
Сравнение нового метода с современными CBM показало его более высокую точность и более понятные объяснения. Однако, несмотря на успехи, остается задача улучшения интерпретируемости без потери точности.
В будущем исследователи планируют изучить решения проблемы утечки информации и увеличить масштаб своего метода, используя более крупные мультимодальные языковые модели для аннотирования больших наборов данных.
Заключение
Исследования MIT представляют собой значительный шаг вперед в области интерпретируемого ИИ, создавая мост к символическому ИИ и графам знаний. Этот подход открывает новые возможности для дальнейших исследований и применения в реальных задачах.